 Photo by Andrew Ridley
Photo by Andrew Ridley
Data Preprocessing - Text Normalization for Tabular Data
Text normalization is a widely used technique by text editing tools. Social media posts, academic papers or any non-edited document may include syntax errors. Edit tools either simultaneously pop up corrected suggestions by predicting what you want to write or give correction feedback by highlighting words to be corrected after the whole document is completed.
Text normalization is also a handy preprocessing tool when it is used for short texts in tabular data. Most businesses have lots of tabular data stored in databases. Even extracting meaningful information from raw tables is a challenging task. Databases store all of the information in a few types of data formats. In most database systems, there are a few main datatypes such as character datatypes, number datatype, date datatype and binary datatype [1]. These types can be classified into two main classes: numeric and categorical.
Categorical variables can be handled if their set size is limited. For example, user gender, customer income group and product color can be mapped into a limited-sized set. In some cases, categorical variables can not be limited by a set of features especially if the variable consists of raw text format. Firm names, product titles and customer addresses can be put in this type.
In some cases categoric information is created by a data entry specialist. For example, official records such as handwritten paper forms are copied into databases by civil servants by hand. In online forms, user information is collected directly from the user and whatever user writes in the textbox is copied into the database. Since users do not care about how the addresses are stored in the database, they could fill the address box with missing information. For that reason, to apply a location-based analysis, the first thing to do is to normalize the address field and map it into a limited-sized set.
For a large amount of data, it is essential to find an efficient method for text normalization. The main idea is finding the most similar source text according to the target text. Text similarity is the key factor when determining the normalized form of the given text. The most popular text similarity method is calculating the edit distance. Edit distance can be calculated by applying the Levenshtein algorithm [2]. The Levenshtein algorithm uses a dynamic programming method and it is efficient when calculating similarity between two words. But calculating similarity for each pair in a long list of texts is not time-efficient. The widely used text representation technique in NLP is helpful in this regard. The method called character based tf-idf vectors can be used to calculate the distance between most similar texts. The below code shows how to extract text representations by using character ngrams.
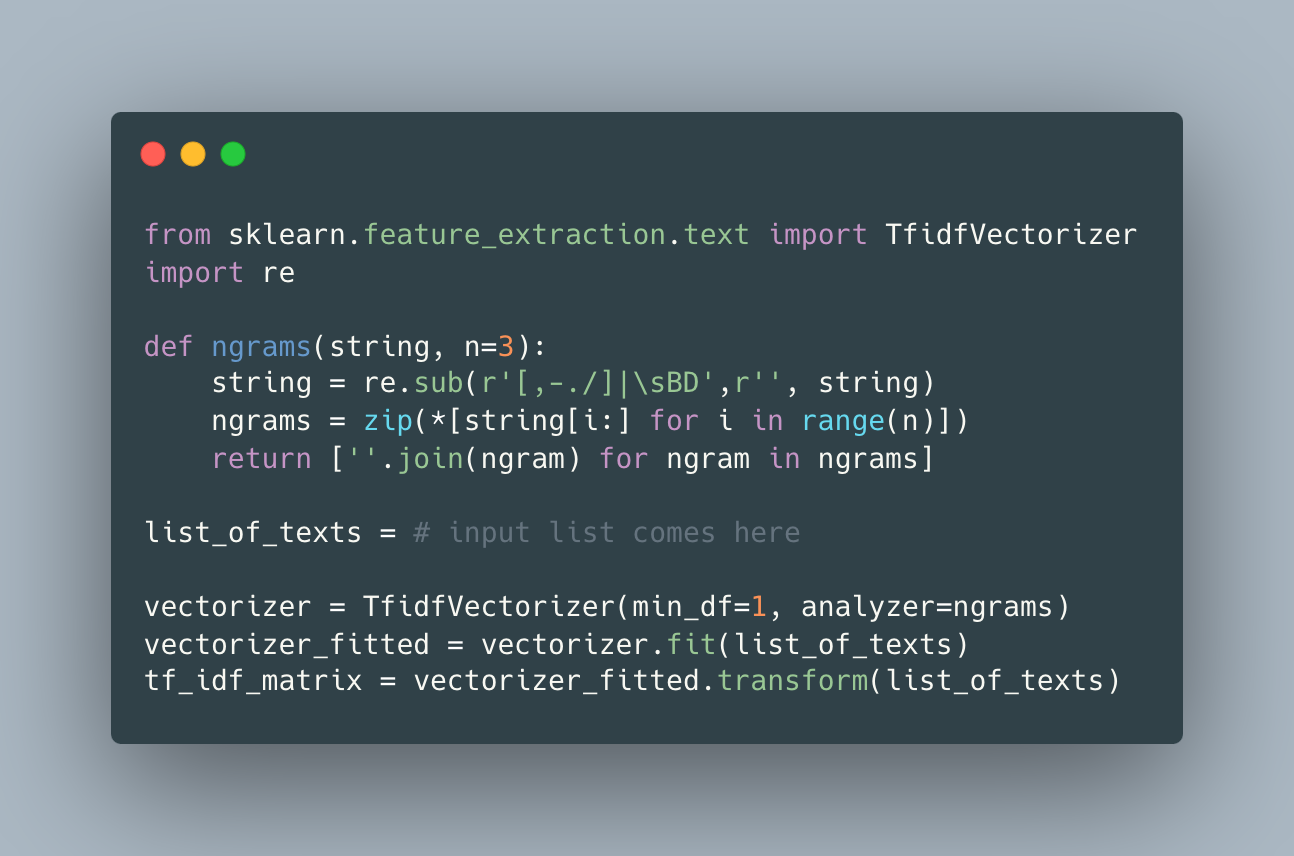
When we represent each text in the same space, the problem turns into finding the closest k vectors for each text vector representation. KNN algorithms have efficient implementations such as ball tree and kd tree that boost nearest neighbor search and make it time-efficient. Below code shows how to create a search index and predict the most similar k texts for a given text.
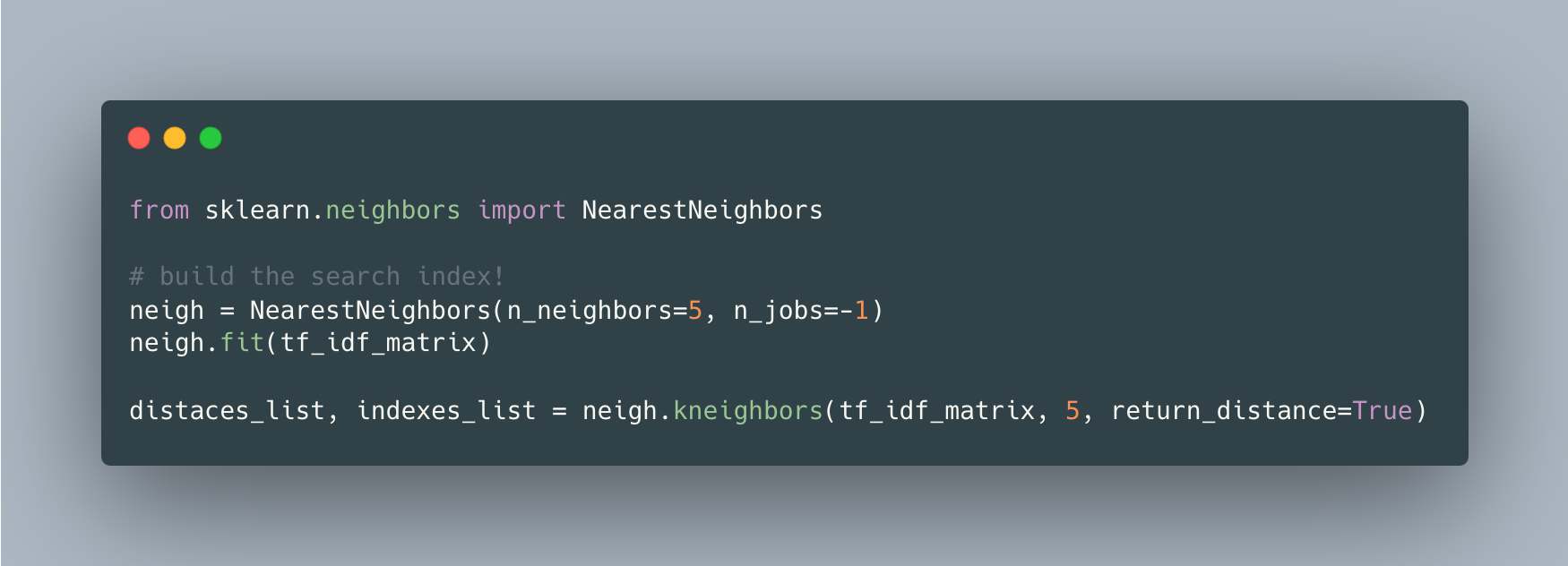
To see in a real application, I shared a full example in the github repo [3]. In this example, the winner firm names in the TED Contract Award Notices data for 2020 [4] are normalized and similar ones are matched with each other. Note that there are different names for an individual firm since the dataset entries are collected from different authorities originating from different countries. I suppose that civil servants are not restricted with a limited set while inserting firm names.
To go with an example, I track ‘mediplus’ through the pipeline since it is the most occured firm name in the raw data. For normalizing firm names, simple preprocessing such as lowering cases, stripping pre/post spaces, and removing punctuation is important. As seen in the below code snippet, by applying simple preprocessing, the number of different firm names including ‘mediplus’ reduces from 10 to 7.
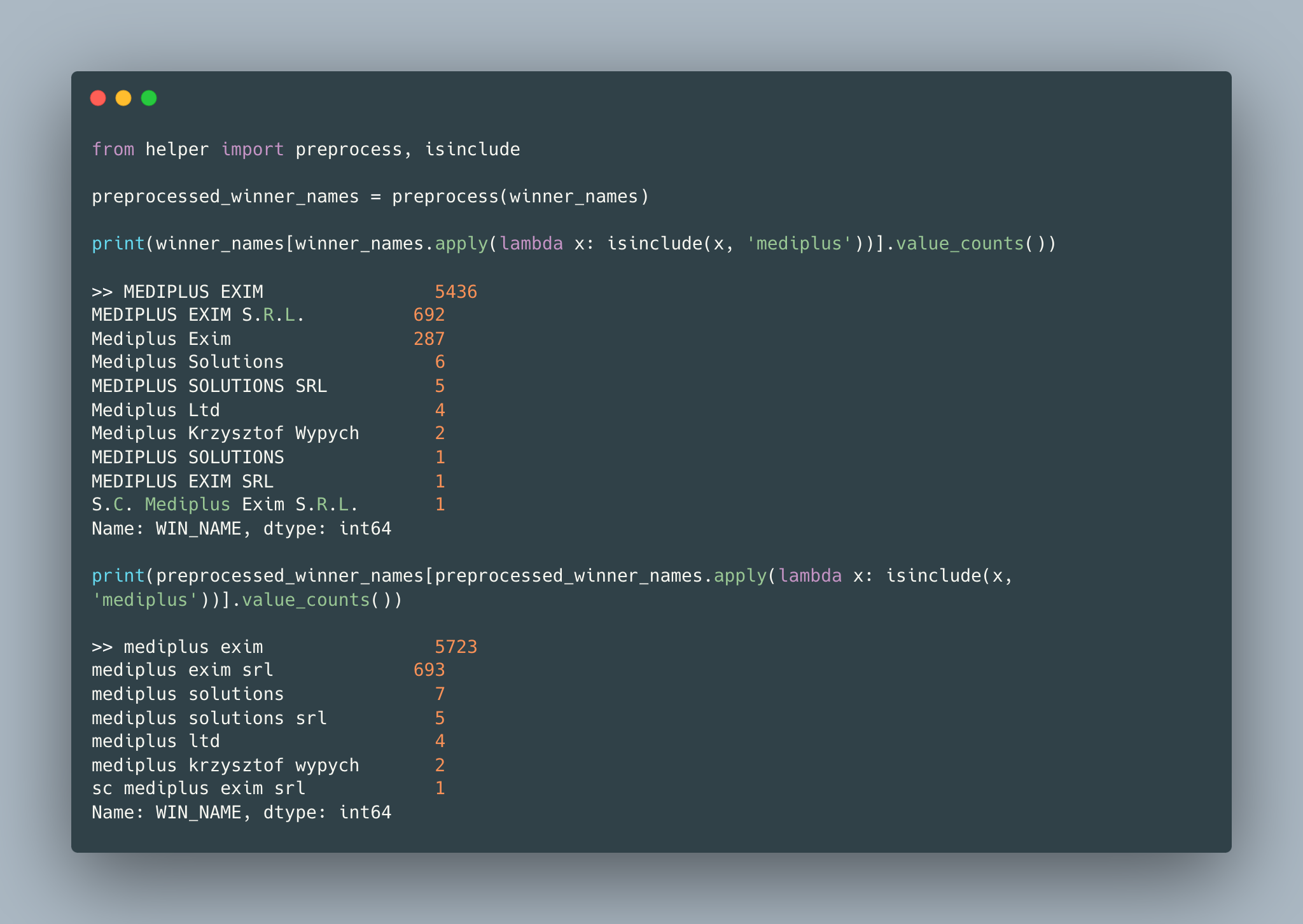
After simple preprocessing, firm names become more similar. Since the domain is procurement winner firms, there are abbreviations such as ‘srl’ and ‘ltd’ followed by firm names. These words can be considered as stop words for this domain. Stop words are the most common words in a corpus and can be distinguished easily according to Zipf’s law [5]. The stop words should be extracted because they do not add any distinguishing feature while calculating text similarity. As seen in the below code snippet, by removing stop words (10 most common words), the number of different firm names including ‘mediplus’ reduces from 7 to 5.
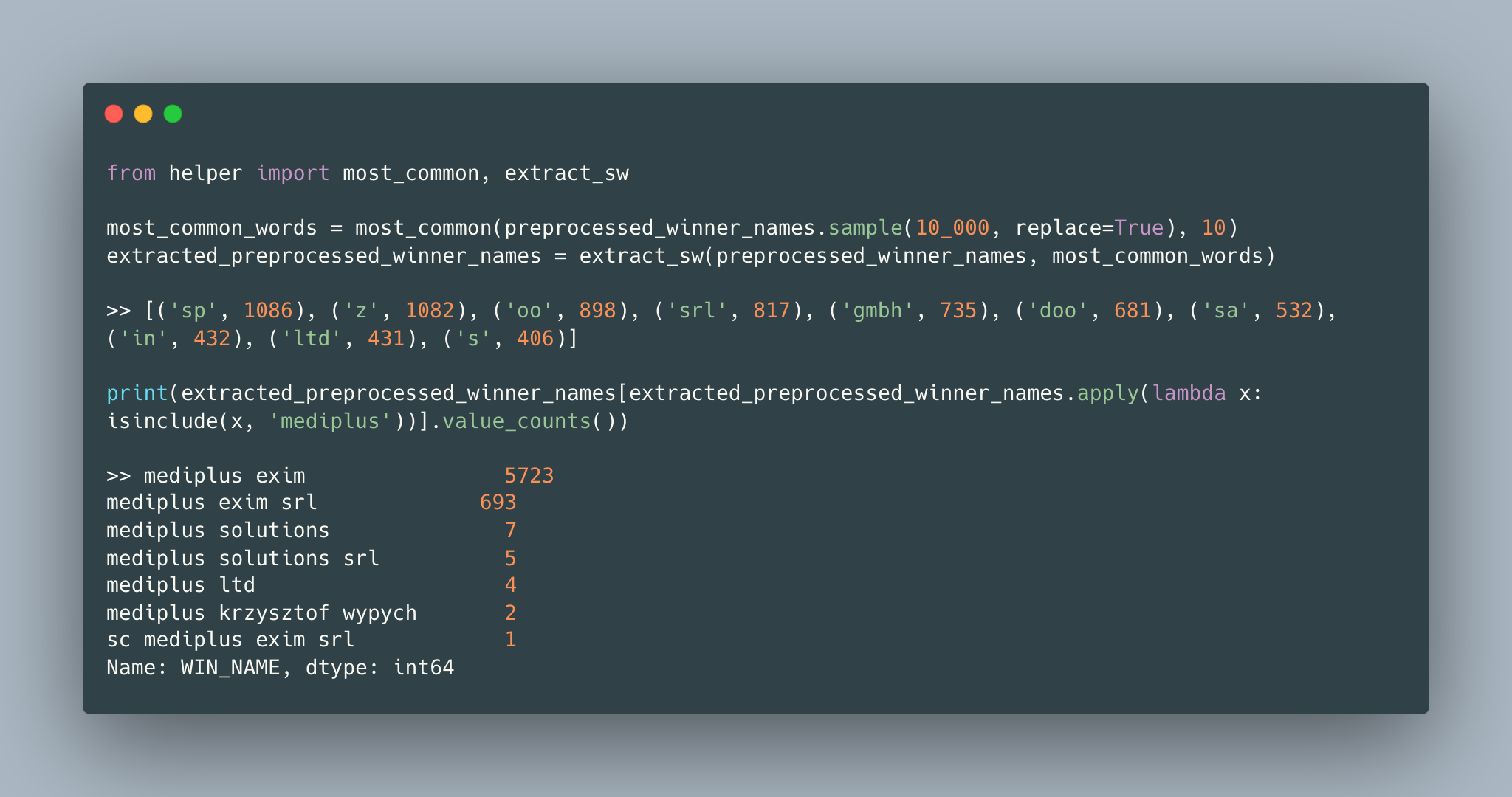
Without a domain expert it is hard to say that the remaining five firms after preprocessing are different firms with similar names or the shareholders of one another. But we have a threshold parameter to adjust the maximum similarity ratio between different firm names. In our example, there does not exist any candidate below the threshold until it is adjusted to 0.6.

But increasing the threshold could cause false matchings. While the threshold is 0.6, the number of different firms containing ‘mediplus’ reduces from 5 to 4. When the threshold is set to 0.8 the result has only 2 different names. But this time, two false matchings occur as ‘mediplan’ and ‘à plus solutions’. That means an exact matching is not possible. Because of that, this operation is also called fuzzy-matching.
There are also other parameters to adjust from the beginning:
- Number of characters that a feature represent in tf-idf vectorizer (selected as 3 gram)
- Number of neighbors (selected as 5)
- Number of most common words (selected as 10)
Note that the stop words could be manually expanded. In our case, ‘exim’, ‘solutions’ and ‘sc’ could be added to stop words.
In this example the search index is built and calculated distances by the data itself. In some cases, text normalization is applied between two datasets. Suppose that there are two datasets about products but the product ids are disjoint sets since datasets coming from different sources. The only common field is the product name column but the names do not match exactly. This is another use case for text normalization. The key point is to construct the search index in the larger dataset to make the process more time-efficient.
In this post, text normalization use cases are summarized and its usage in tabular data is shown by a real example. Thanks for reading..
References
- [1] https://docs.oracle.com/database/121/SQLRF/sql_elements001.htm#SQLRF0021
- [2] https://en.wikipedia.org/wiki/Levenshtein_distance
- [3] https://github.com/mkaang/tabular-text-normalization
- [4] https://data.europa.eu/data/datasets/ted-csv?locale=en
- [5] https://en.wikipedia.org/wiki/Zipf%27s_law